散列表(Hash表)
顺序查找、折半查找、树形结构中的查找,都是基于关键字的比较操作。散列表是摆脱“比较”操作的查找方式。散列表通过关键字和其存储位置之间建立某种关系:若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上,因此不需要比较就可以直接取得所查记录,称这个对应关系f为散列函数(hash函数),按这个思路建立保存记录的查找表称为哈希表。
散列在关键字及其存储位置之间建立某种关系,基于关键字完成记录的访问,既包含了数据元素的存储过程,也能实现数据元素的查找过程。
不同的关键字可能得到同一个散列地址(存储地址),即:key1 != key2,而f(key1) = f(key2),这种现象称为==hash冲突==。将每个关键字映射到哈希表中唯一位置的哈希函数成为理想哈希函数(perfect hashing function)。理想哈希函数不会引起冲突,对表中所有的元素访问的时间都为O(1)。
多数情况下找不到理想hash函数,尽量找一个好的哈希函数,尽量避免hash冲突。
常用的hash函数构造方法
- 直接定址法:取关键字或关键字的某个线性函数值作为散列地址
- 数值分析法:一般取大一点的素数
- 平方取中法:计算关键字值再取中间r位形成一个2^r的表
- 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key % p, p<=m 。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。这是一种最简单,也是最常用的构造哈希函数的方法
- ……
处理hash冲突的方法
链式方法、再散列/哈希法、开放地址法、建立一个公共溢出区…
Hash表查找过程
查找过程中,关键码的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低。因此,影响产生冲突多少的因素,也就是影响查找效率的因素。影响产生冲突多少有以下三个因素:
- 散列函数是否均匀
- 处理冲突的方法
- 散列表的装填因子
散列表的装填因子(负载因子)定义为:α = 填入表中的元素个数 / 散列表的长度。
α是散列表装满程度的标志因子。由于表长是定值,α与“填入表中的元素个数”成正比,所以:
α越大,填入表中的元素较多,产生冲突的可能性就越大;
α越小,填入表中的元素较少,产生冲突的可能性就越小。
实际上,散列表的平均查找长度是装填因子α的函数,只是不同处理冲突的方法有不同的函数。
Java的HashMap解决hash冲突的方法
HashMap采用一种所谓的“Hash 算法”来决定每个元素的存储位置。当程序执行 map.put(String,Obect)方法 时,系统将调用String的 hashCode() 方法得到其 hashCode 值——每个 Java 对象都有 hashCode() 方法,都可通过该方法获得它的 hashCode 值。得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置(对于value:我们完全可以把 Map 集合中的 value 当成 key 的附属,当系统决定了 key 的存储位置之后,value 随之保存在那里即可)。
解决hash冲突使用链表法(链表是单链表):HashMap里面没有出现hash冲突时,没有形成单链表时,hashmap查找元素很快,get()方法能够直接定位到元素,但是出现单链表后,单个bucket 里存储的不是一个Entry,而是一个Entry链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的Entry为止——如果恰好要搜索的 Entry 位于该Entry链的最末端(该Entry是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
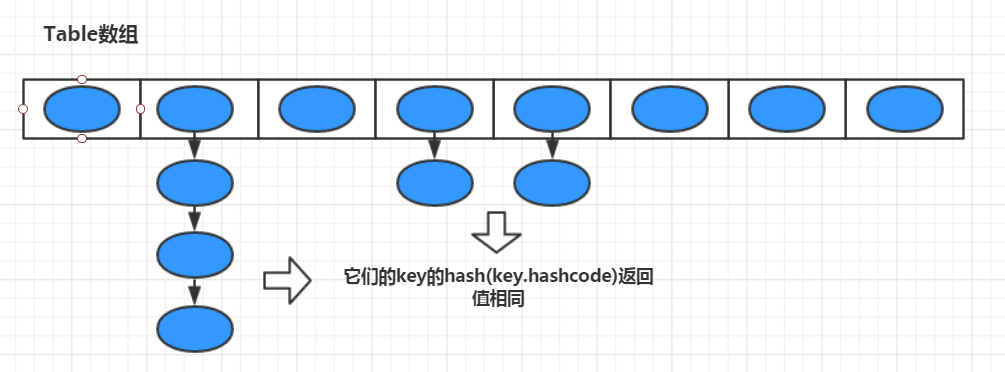
HashMap的链表法解决Hash冲突
当创建 HashMap时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap的 get()与put()方法都要用到查询),减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。